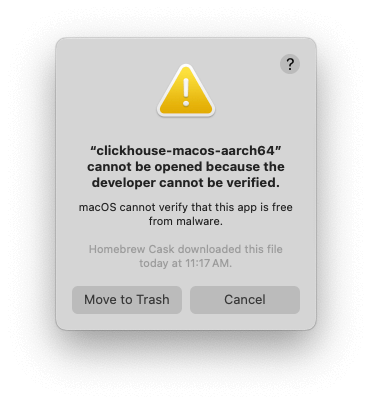
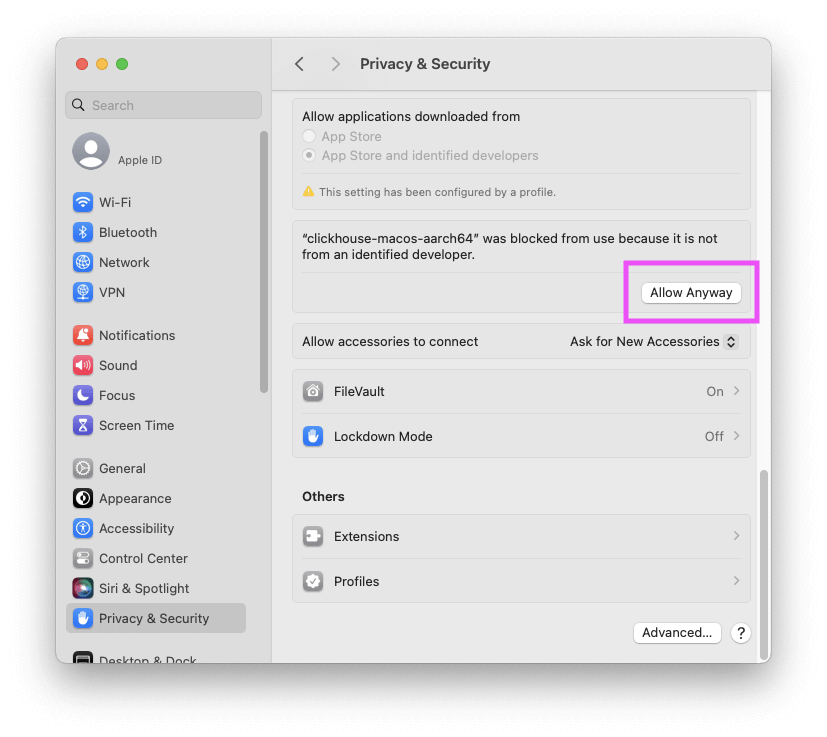
Overview: This article walks through the process of sending data from a Kafka topic to a ClickHouse table. We’ll use the Wiki recent changes feed, which provides a stream of events that represent changes made to various Wikimedia properties. The steps include:
- How to setup Kafka on Ubuntu
- Ingest a stream of data into a Kakfa topic
- Create a ClickHouse table that subscribes to the topic
1. Setup Kafka on Ubuntu
- Create an Ubuntu ec2 instance and SSH on to it:
ssh -i ~/training.pem ubuntu@ec2.compute.amazonaws.com
- Install Kafka (based on the instructions here: https://www.linode.com/docs/guides/how-to-install-apache-kafka-on-ubuntu/):
sudo apt update
sudo apt install openjdk-11-jdk
mkdir /home/ubuntu/kafka
cd /home/ubuntu/kafka/
wget https://downloads.apache.org/kafka/3.7.0/kafka_2.13-3.7.0.tgz
tar -zxvf kafka_2.13-3.7.0.tgz
- Start ZooKeeper:
cd kafka_2.13-3.7.0
bin/zookeeper-server-start.sh config/zookeeper.properties
- Open a new console and launch Kafka:
ssh -i ~/training.pem ubuntu@ec2.compute.amazonaws.com
cd kafka/kafka_2.13-3.7.0/
bin/kafka-server-start.sh config/server.properties
- Open a third console and create a topic named wikimedia:
ssh -i ~/training.pem ubuntu@ec2.compute.amazonaws.com
cd kafka/kafka_2.13-3.7.0/
bin/kafka-topics.sh --create --topic wikimedia --bootstrap-server localhost:9092
- You can verify it was created successfully by:
bin/kafka-topics.sh --list --bootstrap-server localhost:9092
2. Ingest the Wikimedia Stream into Kafka
- We need some utilities first:
sudo apt-get install librdkafka-dev libyajl-dev
sudo apt-get install kafkacat
- The data is sent to Kafka using a clever curl command that grabs the latest Wikimedia events, parses out the JSON data and sends that to the Kafka topic:
curl -N https://stream.wikimedia.org/v2/stream/recentchange | awk '/^data: /{gsub(/^data: /, ""); print}' | kafkacat -P -b localhost:9092 -t wikimedia
- You can "describe" the topic:
bin/kafka-topics.sh --describe --topic wikimedia --bootstrap-server localhost:9092
- Let's verify everything is working by consuming some events:
bin/kafka-console-consumer.sh --topic wikimedia --from-beginning --bootstrap-server localhost:9092
- Hit Ctrl+c to kill the previous command.
3. Ingest the Data into ClickHouse
- Here is what the incoming data looks like:
{
"$schema": "/mediawiki/recentchange/1.0.0",
"meta": {
"uri": "https://www.wikidata.org/wiki/Q45791749",
"request_id": "f64cfb17-04ba-4d09-8935-38ec6f0001c2",
"id": "9d7d2b5a-b79b-45ea-b72c-69c3b69ae931",
"dt": "2024-04-18T13:21:21Z",
"domain": "www.wikidata.org",
"stream": "mediawiki.recentchange",
"topic": "eqiad.mediawiki.recentchange",
"partition": 0,
"offset": 5032636513
},
"id": 2196113017,
"type": "edit",
"namespace": 0,
"title": "Q45791749",
"title_url": "https://www.wikidata.org/wiki/Q45791749",
"comment": "/* wbsetqualifier-add:1| */ [[Property:P1545]]: 20, Modify PubMed ID: 7292984 citation data from NCBI, Europe PMC and CrossRef",
"timestamp": 1713446481,
"user": "Cewbot",
"bot": true,
"notify_url": "https://www.wikidata.org/w/index.php?diff=2131981357&oldid=2131981341&rcid=2196113017",
"minor": false,
"patrolled": true,
"length": {
"old": 75618,
"new": 75896
},
"revision": {
"old": 2131981341,
"new": 2131981357
},
"server_url": "https://www.wikidata.org",
"server_name": "www.wikidata.org",
"server_script_path": "/w",
"wiki": "wikidatawiki",
"parsedcomment": "<span dir=\"auto\"><span class=\"autocomment\">Added qualifier: </span></span> <a href=\"/wiki/Property:P1545\" title=\"series ordinal | position of an item in its parent series (most frequently a 1-based index), generally to be used as a qualifier (different from "rank" defined as a class, and from "ranking" defined as a property for evaluating a quality).\"><span class=\"wb-itemlink\"><span class=\"wb-itemlink-label\" lang=\"en\" dir=\"ltr\">series ordinal</span> <span class=\"wb-itemlink-id\">(P1545)</span></span></a>: 20, Modify PubMed ID: 7292984 citation data from NCBI, Europe PMC and CrossRef"
}
- We will need the Kafka table engine to pull the data from the Kafka topic:
CREATE OR REPLACE TABLE wikiQueue
(
`id` UInt32,
`type` String,
`title` String,
`title_url` String,
`comment` String,
`timestamp` UInt64,
`user` String,
`bot` Bool,
`server_url` String,
`server_name` String,
`wiki` String,
`meta` Tuple(uri String, id String, stream String, topic String, domain String)
)
ENGINE = Kafka(
'ec2.compute.amazonaws.com:9092',
'wikimedia',
'consumer-group-wiki',
'JSONEachRow'
);
- For some reason the Kafka table engine seems to take the public ec2 URL and convert it to the private DNS name, so I had to add that to my local
/etc/hostsfile:
52.14.154.92 ip.us-east-2.compute.internal
- You can read from a Kafka table, you just have to enable a setting:
SELECT *
FROM wikiQueue
LIMIT 20
FORMAT Vertical
SETTINGS stream_like_engine_allow_direct_select = 1;
The rows should come back nicely parsed based on the columns defined in the wikiQueue table:
id: 2473996741
type: edit
title: File:Père-Lachaise - Division 6 - Cassereau 05.jpg
title_url: https://commons.wikimedia.org/wiki/File:P%C3%A8re-Lachaise_-_Division_6_-_Cassereau_05.jpg
comment: /* wbcreateclaim-create:1| */ [[d:Special:EntityPage/P921]]: [[d:Special:EntityPage/Q112327116]], [[:toollabs:quickstatements/#/batch/228454|batch #228454]]
timestamp: 1713457283
user: Ameisenigel
bot: false
server_url: https://commons.wikimedia.org
server_name: commons.wikimedia.org
wiki: commonswiki
meta: ('https://commons.wikimedia.org/wiki/File:P%C3%A8re-Lachaise_-_Division_6_-_Cassereau_05.jpg','01a832e2-24c5-4ccb-bd93-8e2c0e429418','mediawiki.recentchange','eqiad.mediawiki.recentchange','commons.wikimedia.org')
- We need a MergeTree table to store these incoming events:
CREATE TABLE rawEvents (
id UInt64,
type LowCardinality(String),
comment String,
timestamp DateTime64(3, 'UTC'),
title_url String,
topic LowCardinality(String),
user String
)
ENGINE = MergeTree
ORDER BY (type, timestamp);
- Let's define a materialized view that gets triggered when an insert occurs on the Kafka table and sends the data to our rawEvents table:
CREATE MATERIALIZED VIEW rawEvents_mv TO rawEvents
AS
SELECT
id,
type,
comment,
toDateTime(timestamp) AS timestamp,
title_url,
tupleElement(meta, 'topic') AS topic,
user
FROM wikiQueue
WHERE title_url <> '';
- You should start seeing data going into rawEvents almost immediately:
SELECT count()
FROM rawEvents;
- Let's view some of the rows:
SELECT *
FROM rawEvents
LIMIT 5
FORMAT Vertical
Row 1:
──────
id: 124842852
type: 142
comment: Pere prlpz commented on "Plantilles Enciclopèdia Catalana" (Diria que no cal fer res als articles. Es pot actualitzar els enllaços que es facin servir a les referències (tot i que l'antic encara ha...)
timestamp: 2024-04-18 16:22:29.000
title_url: https://ca.wikipedia.org/wiki/Tema:Wu36d6vfsiuu4jsi
topic: eqiad.mediawiki.recentchange
user: Pere prlpz
Row 2:
──────
id: 2473996748
type: categorize
comment: [[:File:Ruïne van een poortgebouw, RP-T-1976-29-6(R).jpg]] removed from category
timestamp: 2024-04-18 16:21:20.000
title_url: https://commons.wikimedia.org/wiki/Category:Pieter_Moninckx
topic: eqiad.mediawiki.recentchange
user: Warburg1866
Row 3:
──────
id: 311828596
type: categorize
comment: [[:Cujo (película)]] añadida a la categoría
timestamp: 2024-04-18 16:21:21.000
title_url: https://es.wikipedia.org/wiki/Categor%C3%ADa:Pel%C3%ADculas_basadas_en_obras_de_Stephen_King
topic: eqiad.mediawiki.recentchange
user: Beta15
Row 4:
──────
id: 311828597
type: categorize
comment: [[:Cujo (película)]] eliminada de la categoría
timestamp: 2024-04-18 16:21:21.000
title_url: https://es.wikipedia.org/wiki/Categor%C3%ADa:Trabajos_basados_en_obras_de_Stephen_King
topic: eqiad.mediawiki.recentchange
user: Beta15
Row 5:
──────
id: 48494536
type: categorize
comment: [[:braiteremmo]] ajoutée à la catégorie
timestamp: 2024-04-18 16:21:21.000
title_url: https://fr.wiktionary.org/wiki/Cat%C3%A9gorie:Wiktionnaire:Exemples_manquants_en_italien
topic: eqiad.mediawiki.recentchange
user: Àncilu bot
- Let's see what types of events are coming in:
SELECT
type,
count()
FROM rawEvents
GROUP BY type
┌─type───────┬─count()─┐
1. │ 142 │ 1 │
2. │ new │ 1003 │
3. │ categorize │ 12228 │
4. │ log │ 1799 │
5. │ edit │ 17142 │
└────────────┴─────────┘
Let's define a materialized view chained to our current materialized view. We will keep track of some aggregated stats per minute:
CREATE TABLE byMinute
(
`dateTime` DateTime64(3, 'UTC') NOT NULL,
`users` AggregateFunction(uniq, String),
`pages` AggregateFunction(uniq, String),
`updates` AggregateFunction(sum, UInt32)
)
ENGINE = AggregatingMergeTree
ORDER BY dateTime;
CREATE MATERIALIZED VIEW byMinute_mv TO byMinute
AS SELECT
toStartOfMinute(timestamp) AS dateTime,
uniqState(user) AS users,
uniqState(title_url) AS pages,
sumState(toUInt32(1)) AS updates
FROM rawEvents
GROUP BY dateTime;
- We will need -Merge functions to view the results:
SELECT
dateTime AS dateTime,
uniqMerge(users) AS users,
uniqMerge(pages) AS pages,
sumMerge(updates) AS updates
FROM byMinute
GROUP BY dateTime
ORDER BY dateTime DESC
LIMIT 10;